Introduction
In the dynamic landscape of customer support, the integration of advanced technologies has given rise to a new frontier in conversational AI. This blog post sheds light on the transformative synergy between Amazon Bedrock FM (Anthropic Claude v2) and Pinecone Vector Database, spotlighting their pivotal role in enhancing Document Question Answering (QA).
As businesses increasingly rely on chatbots to provide instant and accurate support, the ability to extract relevant information from documents becomes paramount. Imagine a chatbot not only understanding user inquiries but also seamlessly retrieving precise answers from extensive documentation. In this exploration, we will explore the capabilities of Amazon Bedrock FM as LLM and Pinecone Vector Database and how their integration empowers chatbots to navigate and comprehend complex documents, ensuring a more intelligent and responsive customer support experience. The example implementation provided serves as an analogy, offering a practical illustration of the concepts discussed.
Amazon Bedrock
Amazon Bedrock offers a fully managed service that provides access to top-tier foundation models (FMs) from leading AI companies via a single API. This streamlined platform, featuring models from AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon itself, comes equipped with a comprehensive set of tools, ensuring the development of generative AI applications with a focus on security, privacy, and responsible AI practices. Amazon Bedrock simplifies the experimentation and evaluation of FMs, allowing users to seamlessly customize models for their unique use cases through techniques like fine-tuning and Retrieval Augmented Generation (RAG). The serverless nature of Amazon Bedrock eliminates infrastructure management hassles, enabling secure integration and deployment of generative AI capabilities into applications using familiar AWS services, marking a significant stride in democratizing AI innovation.
Pinecone
Pinecone offers a cloud-native vector database designed to elevate the efficiency of storing and querying complex data representations. Its strength lies in vector embeddings, a robust form of data that captures semantic information, essential for applications involving large language models. Traditional databases often struggle to keep pace with the intricacies and scale of vector data, but Pinecone excels by providing optimized storage and querying capabilities tailored to the unique requirements of vector embeddings. This results in rapid query results with minimal latency, empowering developers to seamlessly harness the potential of vector embeddings for creating sophisticated AI applications.
I’m a big fan of pinecone features - metadata filtering and namespace features. Namespace within an index allows you to store and group embeddings according to the task name provided. For example you might want to store document chunks on one namespace while storing few shot examples on another namespace within the same index.
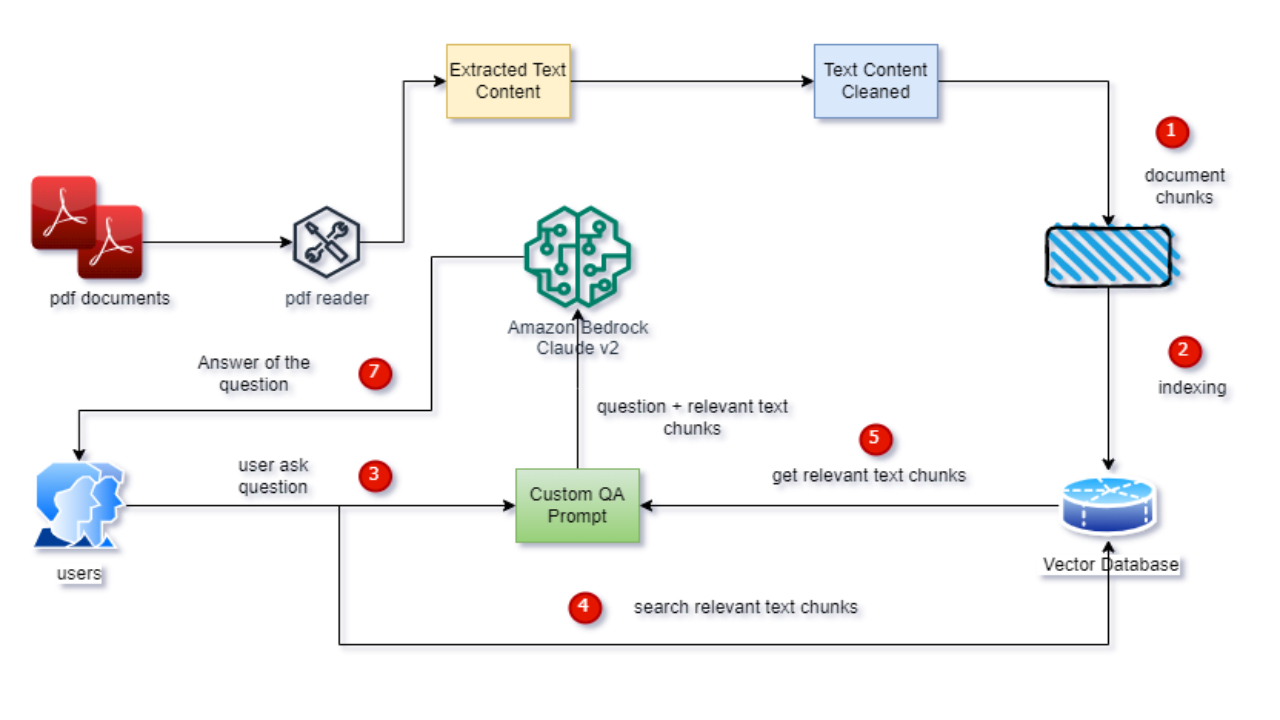
This blog post continues from our previous blog post. In this post, the primary focus is on the creation of document chunks, their storage in the Pinecone vector database, retrieval of relevant text chunks for user questions, and the creation of a Pydantic parser to extract answers from the Language Model.
Setup
For a hands-on experience, sign up for a free instance of Pinecone and export the credentials as environment variables (refer .env.sample file). Additionally, ensure your AWS account has Bedrock enabled in your region. Follow the provided commands for exporting environment variables, setting up notebook server - including the creation of a virtual environment, activation, and installation of necessary requirements.
export PINECONE_API_KEY=<pinecone-api-key>
export PINECONE_ENV=<pinecone-env>
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
jupyter notebook
Replace <pinecone-api-key> with your Pinecone api key and <pinecone-env> with your Pinecone environment.
Implementation
In the previous blog post, we extracted PDF document text, cleaned it, and created summaries using Bedrock with a custom prompt. In this task, we take it a step further by dividing cleaned text into chunks with Langchain’s CharacterTextSplitter, ensuring an overlap for contextual relevance then create MD5 hashes for each text chunk, serving as unique IDs for Pinecone indexing to prevent duplicate indexing. The process ensures efficient storage and retrieval of document chunks, contributing to a streamlined Document QA approach.
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=2048,
chunk_overlap=250,
length_function=len,
is_separator_regex=False
)
This will be used to split the text content into chunks of 2048 characters
def calculate_md5(text):
md5_hash = hashlib.md5()
md5_hash.update(text.encode('utf-8'))
md5_hexdigest = md5_hash.hexdigest()
return md5_hexdigest
This will be used to create MD5 hash of text chunk which will be used by pinecone as unique ID
for doc in tqdm.tqdm(new_documents):
text_chunks = text_splitter.split_text(doc.page_content)
chunk_ids = [calculate_md5(text_chunk) for text_chunk in text_chunks]
chunk_metadatas = [{"chunk": index, "source": doc.metadata["source"]} for index in range(len(text_chunks))]
pinecone_upsert(pinecone_vs, text_chunks, metadatas=chunk_metadatas, ids=chunk_ids)
time.sleep(1)
Process to index vector embeddings of the text chunks and metadata into pinecone index
def pinecone_similarity_search(vectorstore, query, filter={}, k=4):
docs = vectorstore.similarity_search(
query,
k=k,
filter=filter
)
return docs
This function will yield top 4 relevant text chunks for the provided user question
class AnswerParser(BaseModel):
answer : str = Field(description="Answer of the user question based on context provided.")
answer_parser = PydanticOutputParser(pydantic_object=AnswerParser)
Making AnswerParser class using PydanticOutputParser from Langchain. This refines responses to extract only the answer for the provided user question, ensuring consistency.
def get_qa_prompt(question, context, answer_parser):
qa_prompt = PromptTemplate(
template="""Human: You are a world class algorithm for extracting information in structured formats.
You are provided with the user question along with the relevant text chunks to the user question from vector store.
Your task is to answer user question based on the relevant text chunks.
{format_instructions}
Use the given format to extract answer for the following user's question:
{question}
The relevant text chunks are as follow:
{context}
Note:- Make sure to answer in the correct format specified above. \
If you don't know the answer from the provided text context don't try to generate on your own. \
In that case reply with 'I do not having enough context to answer your question.'"
Assistant:
""",
input_variables=["question", "context"],
partial_variables={"format_instructions": answer_parser.get_format_instructions()},
)
return qa_prompt
Making custom prompt to instruct LLM how to generate Answer based on user question and provided text chunk as context
def get_question_answer_from_llm(question, parser):
context = get_text_chunks_from_pinecone(question)
qa_prompt = get_qa_prompt(question, context, parser)
_input = qa_prompt.format_prompt(question=question, context=context, parser=parser)
_output = llm(_input.to_string())
try:
obj = parser.parse(_output)
return obj.answer
except Exception as ex:
print("Failed to parse answer response from LLM", ex)
return None
Function to execute question answer process from LLM
question = "In what ways does AI contribute to the effectiveness of email marketing campaigns?"
answer = get_question_answer_from_llm(question, answer_parser)
print(answer)
Answer from LLM
AI contributes to the effectiveness of email marketing campaigns by helping with tasks such as organizing email lists, personalizing content to target specific audiences, and automating the writing of emails. \This saves time for marketers and allows for better optimization and ROI of campaigns.
Find the complete source code in the following github repository
Conclusion
In the dynamic landscape of conversational AI, the fusion of Amazon Bedrock FM and Pinecone Vector Database stands as a transformative force, reshaping the very essence of Document Question Answering (QA). The increasing reliance on chatbots for instant support propels us into a future where extracting precise information from extensive documents becomes paramount. Visualize a chatbot not only deciphering user inquiries but effortlessly retrieving precise answers from a vast sea of documentation. This exploration has unraveled the distinctive capabilities of Amazon Bedrock FM as a Language Model (LLM) and Pinecone Vector Database, spotlighting their advanced functionalities that elevate customer support to new heights of responsiveness. As we conclude this journey, the reader is left with a vivid understanding of the potential impact — a future where customer support is not just a service but a seamless and intelligent engagement, setting the stage for a paradigm shift in the realm of customer interactions.