Background
Recently, I had the pleasure of presenting a knowledge-sharing session at the Tech Tuesday event hosted by Genese Solution. My talk, “Empowering Data Analysis through LLMs and Vector Databases” showcased the transformative potential of leveraging large language models (LLMs) and vector databases for sophisticated data analysis.
In the modern world, LLMs are revolutionizing various industries by enabling more intuitive and efficient interactions with data. While LLMs are commonly used for advanced chatbots through Retrieval-Augmented Generation (RAG), they also offer powerful capabilities in other areas.
I want to share the research approach we discovered for querying multiple CSV files or SQL tables. We have already seen many people using RAG on textual data, such as making chunks of documents and storing them in vector stores for retrieval. But what if the case involves tabular data like SQL tables or CSV files? We can found articles where people use natural language sentences for CSV rows and columns for the retrieval. For example: let’s say we have following CSV row with column names
id,name,age,city,profession
1,John Doe,30,New York,Software Engineer
The natural language representation for this would be “John Doe is a 30-year-old Software Engineer living in New York.” and then index these type of sentences into vectorstore for retrieval. However this is not scalable; what if we have some financial data where we have to obtained all data rows between certain date ranges. This approach is simply suitable for general question answering which requires few rows into consideration. Another simple way is to feed all the schemas to LLMs and let LLM decide which table to query. However, this approach will only works for schema that are small and can fit into LLM context window and hence is not scalable as well. If there are multiple tables and CSV files, providing all schemas and column names would quickly exceed the context window of the LLMs. We can find other research papers specifically made for analyzing tabular data present in text, but dealing with a large amount of tabular data was the undiscovered thing.
A better approach would be to provide only the relevant schema through a RAG-like method, which we can call a schema extractor or Tabular RAG. We create text descriptions of SQL table schemas, including column descriptions, or CSV file descriptions along with column details. Then, we index them in a vector store. For a user question, we retrieve the top-k table or CSV file descriptions and send them to the LLMs to decide which SQL tables or CSV files could answer the user question. We then generate SQL or pandas code to obtain the desired result.
There are existing libraries or tools for data analysis on CSV files or SQL tables, like PandasAI (Open Source AI Agents for Data Analysis), where we can ask natural language questions to get answers or insights. However, these tools typically handle only one CSV file at a time. But what if we have many CSV files, like 50+ or 100+, and need to ask questions that require combining multiple CSV files?
Our experimented approach is more scalable. We have tested it on around 800 CSV files and were able to correctly retrieve up to 3 CSV files within k=10 retrievals after finetuning the small opensource embedding model on our local machine. This approach is significantly more efficient compared to other State of Art Models (SOTA) currently available in the market like text-embedding-3-large from OpenAI.
In this post, I will explore how LLMs can be used to generate Python code for analyzing CSV files and generating insights. This demonstration will show how we can query CSV files to get natural language answers and derive valuable insights.
Prerequisites
To replicate the demo, we are performing simplier experiment to reterive relevant CSV files for user question. Ensure that you have:
- An AWS account with Claude-3.5 Sonnet LLM Model enabled in region of availability. Alternatively, you can use OpenAI models like gpt-4o.
- If using AWS, create access key and secret key with Bedrock full access for simplicity. You can be more permissive here for setting up permission. You can set up profile by exporting credentials using command -
aws configure --profile your-profile-name - Created a Pinecone account and should have Pinecone API key for data indexing
Tools and Technologies Used
Claude 3.5 Sonnet as LLM
Claude-3.5 Sonnet is a cutting-edge language model known for its intelligence, speed, and cost efficiency. It can be accessed via the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. I’ve chosen it because it was enabled in my aws account.
Pinecone
Pinecone is a managed, cloud-native vector database designed for long-term memory in high-performance AI applications. It offers a simple API and serverless indexes that scale automatically based on usage, optimizing costs and elasticity. Best part is you can get started with one free index, and within that, create multiple namespaces to tailor storage for different use cases.
Langchain
LangChain is a framework I’ve found incredibly useful for simplifying the development of applications using large language models (LLMs). It’s designed specifically to streamline tasks like document analysis, summarization, building chatbots, and even code analysis.
Langgraph
LangGraph is a library designed for building stateful, multi-actor applications using LLMs. It supports agent and multi-agent workflows, providing capabilities such as cycles, controllability, and persistence. LangGraph enables the creation of reliable agents with precise control over application flow and state management. We utilized LangGraph specifically to manage conditional flows, such as when code execution fails, redirecting to fallback responses like “Unable to generate executable code for your query.”
Streamlit
Streamlit allows you to turn Python scripts into interactive web apps quickly. It’s ideal for building dashboards, generating reports, or creating chat apps. Streamlit supports fast, interactive prototyping with live editing, and it’s open-source and free. We utilized Streamlit to seamlessly convert a notebook script into a dynamic web application.
Datasets Used
We utilized CSV files available from site DATA.GOV
Border_Crossing_Entry_Data.csv - Statistics for inbound crossings at U.S.-Canada and U.S.-Mexico borders.
Employment_Unemployment_and_Labor_Force_Data.csv - Maryland’s labor force participation, employment, and unemployment rates.
NYPD_Shooting_Incident_Data_2006.csv - NYC shooting incidents data from 2006 onwards.
Warehouse_and_Retail_Sales.csv - Monthly sales and movement data by item and department.
Application Overview
Clone the git repository from here
Change directory to 03_code_execution_agent you can see the folder structure like below
├── 00_code_agent.ipynb
├── 01_code_agent-with-langgraph.ipynb
├── 02_code_agent_updated.ipynb
├── datasets
│ ├── description
│ │ ├── Border_Crossing_Entry_Data.txt
│ │ ├── Employment_Unemployment_and_Labor_Force_Data.txt
│ │ ├── NYPD_Shooting_Incident_Data_2006.txt
│ │ └── Warehouse_and_Retail_Sales.txt
│ ├── Border_Crossing_Entry_Data.csv
│ ├── Employment_Unemployment_and_Labor_Force_Data.csv
│ ├── NYPD_Shooting_Incident_Data_2006.csv
│ └── Warehouse_and_Retail_Sales.csv
├── app.py
├── pinecone_upsert.py
├── README.md
└── requirements.txt
There are some notebook files used before creating the streamlit application which is app.py.
Script pinecone_upsert.py consists of logic to make CSV file description and index them to Pinecone vectorstore.
Make sure to make a python virtual environment and activate before installing dependencies from requirements.txt
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
And then export the Pinecone API key obtained from Pinecone dashboard.
export PINCONE_API_KEY=your-pinecone-api-key
After exporting the API key for pinecone make sure to run the upset script using command
python pinecone_upsert.py which will index the CSV file description to the vectorstore.
After indexing just run streamlit application using command streamlit run app.py or
you can play around with the notebook script by running command jupyter notebook --port 8888
Application flow
-
When the user ask the question we find relevant CSV file description from pinecone index.
-
Extract CSV file path from metadata of the retrieved document from vectorstore.
-
Make context to extract correct CSV file path in json format for the user question with the help of prompt below.
csv_file_path_prompt_template = """\ You are provided with csv files with their file description and 2 sample rows in markdown format for additional context. You are also provided with user question and your task is to return csv file paths that could answer the user question. User question is as follow: {question} CSV file context is as follow: {csv_file_context} Please give your final response in the format specified below: {format_instructions} NOTE: NO PREAMBLE AND NO POSTAMBLE. JUST GIVE THE DESIRED RESPONSE ONLY IN THE JSON FORMAT SPECIFIED ABOVE. Your response: """ -
Use
create_python_agentfrom Langchain with custom prompt (can be found in the code) to generate and execute python code. We save results (dataframeandfigure) to new file paths to display in the streamlit UI. -
If code is unable to execute even with multiple retries we route the execution flow to fallback node where task is to display some message like “Failed to execute the code generated by LLM” or something like that.
-
If the generated code is executed successfully then we continue to the another step of natual language answer generation from LLM based on the resulting dataframe obtained from the code execution.
We used LangGraph to orchestrate this flow and is shown in the diagram below.
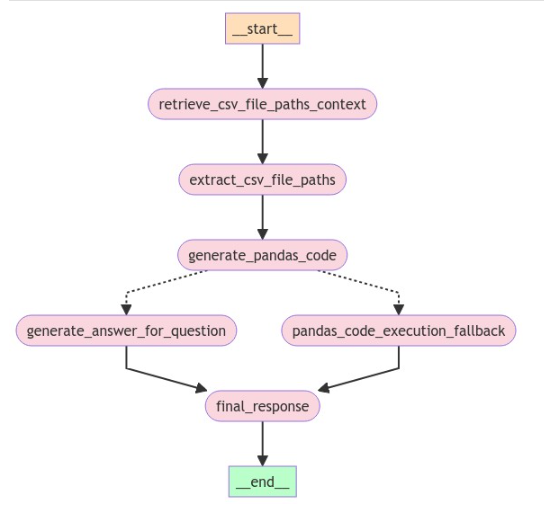
Figure: Application flow diagram generated from Langgraph.
Sample App Output
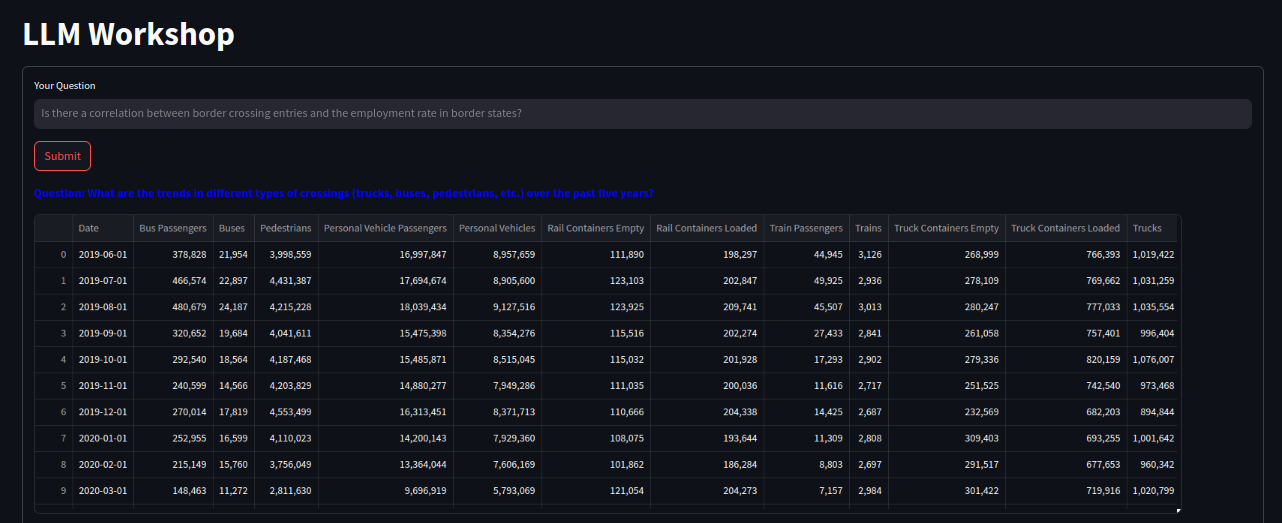
Figure: Output dataframe.
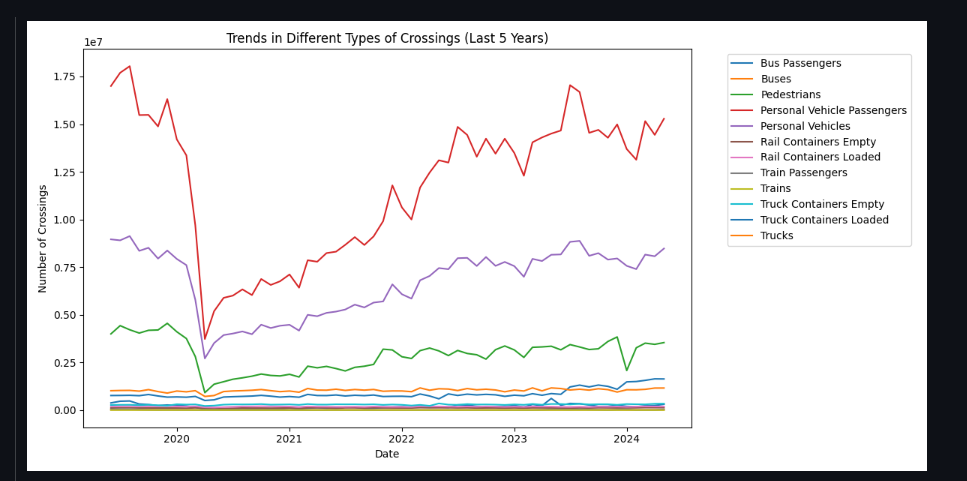
Figure: Output Graph.

Figure: Output Answer.
Conclusion
In today’s data-driven world, integrating large language models (LLMs) with vector databases is revolutionizing data analysis. LLMs simplify complex data queries into natural language questions, enhancing our ability to uncover insights from structured data such as CSV files and SQL tables. Our approach leverages vector databases to extract the most relevant schemas, aiding in answering queries. Then, LLMs precisely extract required schemas from these candidates to generate executable code, optimizing data processing and analysis. This integration streamlines decision-making processes across various fields, showcasing the transformative potential of LLMs in modern data analytics.