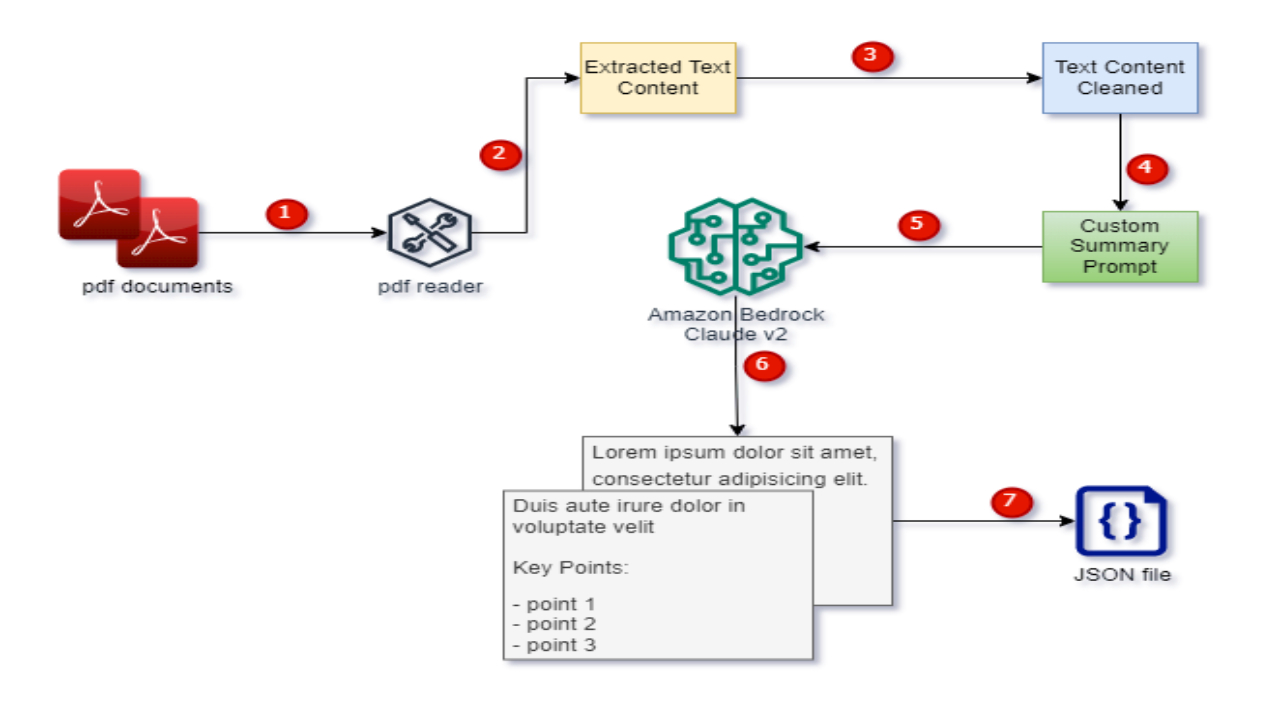
Introduction
Welcome to the realm of document summarization, where complexity meets simplicity! This blog post is your key to clarifying the complexities of crafting concise summaries using the Bedrock Claude v2 Model and custom prompts. In the vast ocean of information, summaries are like guiding stars. They help us swiftly capture the essence of documents, saving precious time and energy. Our mission is to demystify the process, ensuring document summarization becomes an accessible skill for all. By the end of this post, you’ll not only understand the process but also be empowered to create your own concise summaries using your own format instruction. Let’s embark on this adventure together!
Setup
We must have an AWS account with Bedrock enabled in the required region. I’ll use an IAM user with an Admin role for simplicity, but secure configurations are recommended. Configure our AWS CLI profile using aws configure --profile <profile-name> this profile name will be used later while accessing Bedrock through boto3.
Our adventure begins by setting up a Jupyter notebook. Create a virtual environment, activate the virtual environment and install the dependencies listed in the requirements.txt file then start the jupyter notebook server. Run the following command to do so.
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
jupyter notebook
And we’re ready to set sail.
PDF Source
I choose my company blog posts as my PDF source for summarization, to be safe from piracy while using other’s PDFs. Since these PDFs are from the blog post, we have to clean up the PDF content to eliminate unnecessary sections like blog post list section or comment forms section.
def get_cleaned_page_content(page_content):
## remove url patterns
url_pattern = re.compile(r'https?://\S+|www\.\S+')
page_content = url_pattern.sub('', page_content)
try:
social_pattern = r'Facebook \d+\n\n'
result = re.split(social_pattern, page_content)
page_content = result[0]
except:
pass
return page_content
We removed company website present in the different section of the text and also truncate the text by Facebook button text. You can find these in the text content before cleanup.
Crafting Simple Prompts for LLM
Large Language Models (LLM) require clear instructions to generate consistent responses. Crafting prompts is like giving the right set of directions. Our designed prompts provide an overall theme followed by key bullet points. We instruct LLM to strictly follow guidelines, exclude any personal information, and avoid unnecessary text at the start and end by giving key words “NO PREAMBLE and NO POSTAMBLE”.
def get_summary_prompt(text):
summary_prompt_template = PromptTemplate(
template="""Human: You are provided with the text content from a pdf document.
Your task is to summarize the text content provided below.
{text}
Note:- Discard PII information if present any.
NO PREAMBLE and NO POSTAMBLE
Always follow the below instruction to generate summary of the content -
First few 3 to 4 lines in a pagraph will give summary in paragraph mode then will followed by key points as summary.
For example:
The article discusses the relevance of email marketing in 2023 and explores various trends impacting this marketing strategy and so on.
Key Points:
- point 1
- point 2
...
Assistant: Here is the summary of the text provided \n\n
""",
input_variables=["text"]
)
summary_prompt = summary_prompt_template.format_prompt(text=text).to_string()
return summary_prompt
Summarizing with Bedrock Claude v2
We load PDF documents using the Unstructured package, extracting page content and metadata. Cleaning the page content and combining it with our crafted prompt creates a custom summary prompt. Bedrock Claude v2 takes the stage, transforming the input into a concise summary. We log this summary in a JSON response, paving the way for potential frontend rendering and user interaction.
def get_llm_summary(page_content):
summary_prompt = get_summary_prompt(page_content)
summary_result = llm(summary_prompt)
return summary_result
Function defined to get the summary from the LLM.
summaries = []
for doc in tqdm.tqdm(new_documents):
summary = get_llm_summary(doc.page_content)
summaries.append({"source": doc.metadata["source"], "summary": summary})
df = pd.DataFrame(summaries)
df.to_json('summaries.json', orient='records')
To log the summary generated into json file by iterating through the available pdf documents.
Find the complete source code in the following github repository
Conclusion:
And there you have it! Our adventure into document summarization is coming to a close. We’ve discovered that using Bedrock Claude v2 and clever prompts can help us make sense documents. Summarizing isn’t a secret skill; it’s something everyone can get the hang of with the right tools. So, as you go on your own summarization journey, remember – it’s about making things simple and easy to understand. Enjoy summarizing!
Next Up
As we wrap up this chapter, get ready for our next exciting adventure! We’ll dive into the world of extracting text chunks from the vector store, filtering them by source, and using the magic of Bedrock to generate natural language answers for any questions users might ask.